

Die optische Zeichenerkennung ist auch im industriellen Umfeld ein wichtiges Verfahren. Denn mittels industrieller Bildverarbeitung lassen sich Werkstücke und Produkte entlang der gesamten Wertschöpfungskette anhand aufgedruckter oder eingestanzter Zeichen sicher identifizieren. Mithilfe moderner Deep-Learning-Technologien und neuronaler Netze können bestimmte Fonts so trainiert werden, dass sich die Erkennungs-raten von Schriften entscheidend verbessern.
Johannes Hiltner, Product Manager Halcon, MVTec Software
Methoden der optischen Zeichenerkennung (Optical Character Recognition / OCR) sind bisher vor allem aus der Bürokommunikation bekannt: Durch Einscannen von Dokumenten in Papierform wie etwa Rechnungen, Lieferscheinen und sonstigen Belegen lassen sich diese schnell in eine digitale Form bringen, relevante Informationen daraus extrahieren und diese dadurch in einen durchgängigen, elektronischen Informationsfluss einbinden. Doch auch in industriellen Konstruktions- und Produktionsprozessen spielt das Verfahren eine zunehmend wichtige Rolle, und zwar insbesondere im Kontext von Industrie 4.0: Durch aufgedruckte Buchstaben- oder Zahlenkombinationen lassen sich Bauteile eindeutig und schnell identifizieren und für automatisierte Prozessketten bereitstellen.
Bei der optischen Zeichenerkennung nehmen Bildeinzugsgeräte wie etwa Scanner oder Kameras dazu digitale Bildinformationen auf und erstellen daraus Rastergrafiken, die den Text pixelgenau darstellen. Eine OCR-Software liest diese Grafiken aus, erkennt darin Zahlenkombinationen oder Buchstaben und setzt sie – in Konstruktions- und Produktionsprozessen unterstützt durch Verfahren der industriellen Bildverarbeitung (Machine Vision) – zu Wörtern oder sogar ganzen Sätzen zusammen. Für die besonderen Anforderungen im Industrieumfeld enthält die Machine-Vision-Software dafür spezifische Funktionen.
Robuste Texterkennung durch künstliche Intelligenz
Beispielsweise erlauben durchdachte Klassifikationstechniken auch unter schwierigen Bedingungen sehr hohe Erkennungsraten. Auch unscharfer oder schräg gestellter Text lässt sich problemlos identifizieren – selbst mit verzerrten Buchstaben oder Zeichen, die auf reflektierenden Oberflächen oder stark strukturierten Farbhintergründen gedruckt oder geätzt wurden. Da industrielle Anwendungsfelder immer schnellere und flexiblere Prozesse erfordern, fließen auch Verfahren der künstlichen Intelligenz in die Bildverarbeitung ein: Deep-Learning-Algorithmen und künstliche neuronale Netze wie Convolutional Neural Networks (CNN) sorgen beispielsweise für noch robustere Ergebnisse bei der Texterkennung.
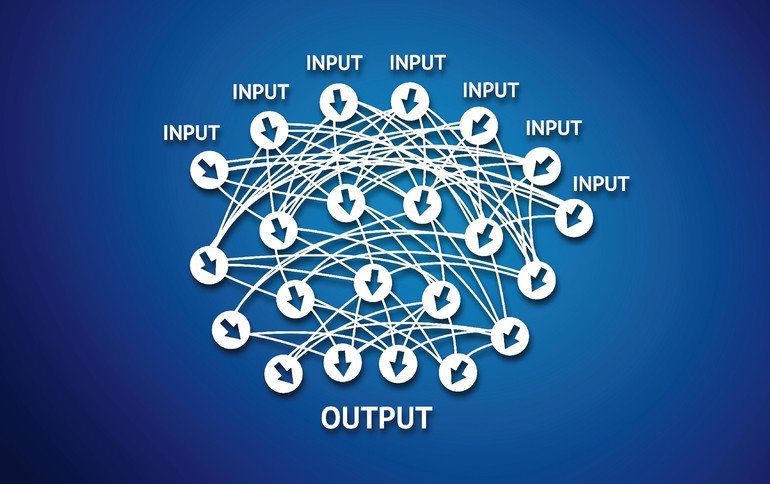
Deep-Learning-Technologien zeichnen sich dadurch aus, dass große Mengen an digitalen Bilddaten analysiert und somit Modelle von bestimmten, zu erkennenden Objekten trainiert werden können. Dies funktioniert bei physischen Gegenständen ebenso wie bei Buchstaben oder Zahlen. Dabei werden die Daten mit einem Label versehen, der die Identität des Objekts angibt, wie zum Beispiel „Hund“ oder „Buchstabe A“. Anhand der trainierten Modelle lassen sich nun zielsichere Aussagen über die Inhalte und Motive neu aufgenommener Bildinformationen treffen. Die Technologie lernt also mit jedem zusätzlichen „gelabelten“ Bild dazu. Dadurch steigt auch die Wahrscheinlichkeit, möglichst viele verschiedene Ausprägungen der Bildinhalte, wie beispielsweise andere Hundearten oder Zeichen mit variierenden Schrifttypen oder Verformungen verlässlich zu erkennen. Die einzelnen Objekte lassen sich also zielsicher in entsprechende Klassen einteilen. Dies ermöglicht eine voll automatisierte, eigenständige Erkennung, ohne dass dem System für jedes Objekt explizit ein Beispielbild zur Verfügung gestellt werden muss.
Selbstlernendes System für die Klassifizierung
Um eine hohe Erkennungsrate zu gewährleisten, berücksichtigen die Algorithmen die Merkmale aller aufgenommenen Bildinformationen. So lernt das System, welche Eigenschaften eine bestimmte Klasse repräsentieren. Beispielsweise wird automatisch erkannt, welche Merkmale für die Klasse „Hund“ sprechen oder welche äußeren Eigenschaften typisch für die jeweiligen Buchstaben oder Zahlen sind. Dabei lernt die Technologie auch aus Fehlern: Ist während des Trainierens eines Netzes das Ergebnis nicht korrekt, werden Parameter angepasst und der Prozess startet neu. Auch die Fehlererkennung basiert auf der Analyse großer Mengen digitaler Bilddaten, wodurch das System automatisch Abweichungen feststellt. Dieses iterative Vorgehen wiederholt sich so lange, bis das Modell optimal für die Anwendung trainiert ist. Hierbei zeigt sich auch der Hauptunterschied zwischen klassischem maschinellen Lernen und Deep Learning: Letzteres erfordert keine Merkmale, die der Entwickler mühsam manuell definieren und verifizieren muss, sondern nutzt vielmehr lernende Algorithmen, um die eindeutigen Muster zur Unterscheidung von Klassen automatisiert zu finden und zu extrahieren. Moderne Machine-Vision-Lösungen nutzen die beschriebenen Deep-Learning-Technologien für die optische Zeichenerkennung: Halcon 13 beispielsweise, das aktuelle Release der Bildverarbeitungs-Software von MVTec, enthält einen, auf Deep-Learning-Algorithmen basierenden OCR-Klassifikator, auf den über zahlreiche vortrainierte Schriften zugegriffen werden kann. Damit lassen sich wesentlich höhere Leseraten als mit sämtlichen bisherigen Klassifikationsmethoden erzielen.
Möglichkeiten moderner Machine-Vision-Lösungen
Die Software ermöglicht dadurch auch die robuste Erkennung von Dot-Print-, SEMI-, industriellen und dokumentenbasierten Schriftarten mit nur einem, universell vortrainierten Font. Davon können Unternehmen enorm profitieren: Für das Training wird in der Regel eine sehr hohe Anzahl von Bildern benötigt – bis in den sechsstelligen Bereich. Durch die Bereitstellung vortrainierter Fonts lässt sich also sehr viel Zeit einsparen. Die verbesserte Zeichenerkennung konnte zudem in Testreihen mit einem sehr anspruchsvollen Datenset nachgewiesen werden – dabei ließ sich die Fehlerrate in Bildern mit vielen verschiedenen Zeichen in variierenden Größen, Formen, Schrifttypen und Qualitäten sogar halbieren. Dadurch können Objekte zuverlässiger identifiziert und fehlerhaft produzierte oder bedruckte Objekte eindeutiger erkannt und aussortiert werden. OCR-Verfahren sind somit in industriellen Engineering- und Produktionsprozessen für die automatisierte Erkennung von Objekten mittels aufgedruckter Zahlen- oder Buchstabenkombinationen mittlerweile unverzichtbar. ik
Teilen:







{kind=link}